I recently commented on a LinkedIn post about the power of LinkedIn as a content marketing platform. The gist of the post was that it is rapidly becoming the go-to platform for branded content marketing. I disagreed with the very premise of the post.
I get that LinkedIn has a lot of appeal as a central place to find people. My problem with LinkedIn is I can’t find content in the platform. As if to prove my point, I went looking for the post I commented on and couldn’t find it. After striking out with LinkedIn search, I searched in Google. No luck. I got a lot of results, but none of my numerous queries produced the result I was looking for. And I’m a power user of Google.
Contrast that to Wikipedia: not only is it easy to find content within the platform, Wikipedia articles are all over the first page in Google. You might wonder why this is. Well, some of it is about the content itself, as my colleague and friend Charles Chesnut showed in his maiden post on this platform: The Wikipedia test for content marketing. Beyond the content itself, a big reason for the success of Wikipedia content is findability. This is one of my laws of content strategy:
The value of content increases in proportion to how easy it is to find.
So why is content so easy to find in Wikipedia and hard to find in LinkedIn? I contend that the URL structure of the two platforms is a key reason. In particular, the semantics of the URLs plays a big part of how search engines index the content, and ultimately rank the content in their indices. LinkedIn’s URLs are organized the way the whole site is: by people’s names. Wikipedia’s URLs are organized primarily by topics.
When people are looking for content, more often than not, they search by topic. If you study search queries as I do for a living, this would become obvious fairly early on. Yes, people sometimes search for people, when they are looking for an expert on a topic they already know about. But if they are just getting into a field of study, they search by topic. The vast majority of queries are by people who are learning about things outside of their areas of expertise.
In my research, about 80% of queries relevant to our audience are what we call informational queries: Composed of keywords about generic topics. About 15% of the queries we track are what we call navigational queries: composed of keywords about brands, people, and company names. About 5% of queries are transactional: composed of product names and model numbers. I’ve been tracking query trends for 10 years. Topics come and go, but these percentages don’t change much.
Besides the ranking bias search engines have for high-quality topical content, one reason Wikipedia dominates in search is its URL semantics are almost entirely based on topics. Search engines organize content in their indices by keywords. Keywords are grouped as sets of topics. When search engines crawl a site, they look at the URL structure to see how it lines up to their topical hierarchy in their indices.
A topical hierarchy allows search engines to put the content in the site into the right buckets in their indices. If you have good content in each of these buckets, you have a chance to rank for those topics. If search engines can’t figure out where to index your pages, you have little chance to rank for those topics.
One of the big challenges I have as an SEO for a mammoth site is how many pages Google puts into its index for each keyword cluster. Using Google’s Site: operator function in the Search Console, we can see what pages Google puts into its index for any given keyword. We can then diagnose why it indexes some content and not others in its index for some keywords. In my experience, the URL structure is the strongest signal we can send Google to help it index our content into the right buckets.If we bury good content about a topic below a product name in the URL, for example, that content often doesn’t have a chance.
Following Wikipedia, we are reorganizing our site into topical URL structures, which should help Google put it into the right buckets. Perhaps as important, we are cleaning out old, low-quality pages that Google currently indexes for our audience’s most queried keywords. This should help it rank the best page we have in its index for those keywords.
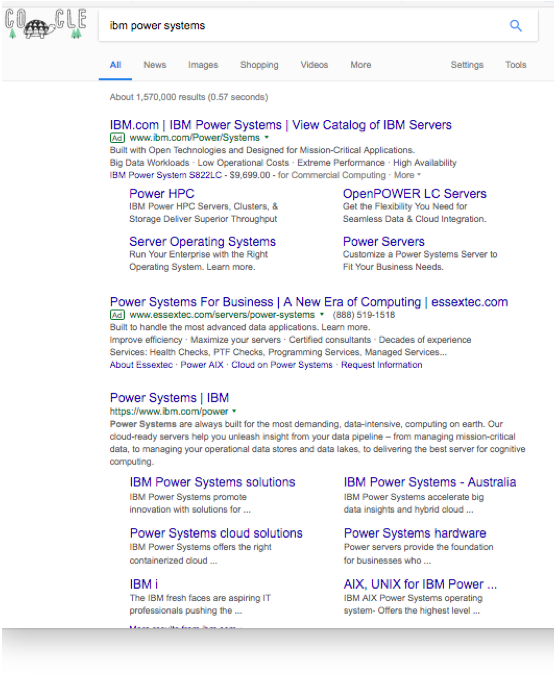
Early results look really good. Among many other benefits, because Google understands what our pages are about from a URL perspective, we get all kinds of site links. Site links are additional references deeper within a topic on a site, as this picture shows. Now, we won’t get site links for generic topics like servers. But when users type transactional queries such as product names, we can get them to the right place directly from the search engine.